이번 글에서도 저번처럼 현재 읽고 있는 논문0)을 읽으면서 중요하다고 생각되는 몇 가지 개념들에 대해 가볍게 정리하고 가도록 하겠습니다.
[12일차] 논문 공부 :: Chromogenic IHC와 Immunofluroscence(IF), Cell fixation with PFA
이번 글에서는 전 글에 이어 논문 관련 이론 정리를 하는 시간을 가져보도록 하겠습니다. [12일차] 논문 관련 이론 정리 :: Tet-On & Tet-Off System, IRES와 2A peptide전 글에서 말씀드렸듯이, 요즘 Zotero를
tkmstudy.tistory.com
처음 이렇게 여러 개념들을 하나하나 정리해가면 나중에 다른 논문을 읽을 때 좀 더 수월하게 읽을 수 있지 않을까 기대해봅니다.
지금은 거의 다 생소하거나 제대로 모르는 것들이라서 정리할 게 너무 많은 것 같습니다.
5. DMEM / F12
DMEM(Dulbecco's Modified Essential Medium)은 전공수업 때 배웠었던 기억이 나는데요, 세포 배양에 사용된 배지로 MEM에 비해 4배 이상의 비타민과 아미노산, 글루코스(일명 세포밥), 그리고 추가적인 보충물들이 포함된 세포배양에 광범위하게 사용되는 동물세포 배양용 배지1)입니다.
DMEM/F12는 이러한 DMEM에 무혈청 배지인 Han's F12를 1:1의 비율로 혼합한 배지로 고농도의 세포밥들 뿐만 아니라 Han' F12의 다양한 성분들이 들어 있어서 혈청(serum) 사용량을 줄이거나 무혈청의 조건을 세포를 배양하기 위한 기본 배지로 많이 사용한다2)고 합니다. 아래 영상을 보시면 동물 세포 배양 배지에는 어떤 종류가 있는지 쉽게 이해가 되실 수 있을 듯 합니다.
여기서 serum은 다양한 성장 인자들(ex. 세포 생장과 분열에 도움을 주는 mitogens 포함)이 있어서 특정 조건에선 세포 배양에 유용하게 활용할 수 있긴 하지만, scRNA-seq을 진행하는 샘플을 준비할 땐 혈청의 영향을 줄이는 DMEM/F12를 사용했다고 합니다. 그 이유는 혈청엔 RNases(RNA 분해 효소)와 같은 동물 유래 오염 물질이 있을 수 있어3) 결과 값에 영향을 미칠 수 있기 때문으로 추측됩니다. 제가 한 건 아니라서 그렇지 않을 수도 있습니다.
읽고 있는 논문0)에선 소장 상피세포들을 차가운 DMEM/F12로 세번 정도 씻어낸 후 90%의 cell viability를 갖는 single-cell suspsension에 대해 10X Chromium Controller로 library preparation을 진행하였고, Bioanalyzer로 quality control(QC)을 한 후 NovaSeq 6000라는 ILLUMNIA의 NGS 장치를 활용해 시퀀싱을 진행하였다고 합니다. 'Novaseq 6000'에 대해선 나중에 글 하나로 기술 정리를 해보려고 합니다.
NovaSeq 6000 System | Powerful sequencing with scalable throughput
Tunable output for mix and match options Do what you want. Mix and match flow cell types and run one or two flow cells at a time. Choose between multiple read lengths, workflows, and more.
www.illumina.com
6. Highly Variable Genes (HVGs)
HVGs는 homogeneous(동질)한 cell population에서 cell-to-cell variation에 강하게 기여하는 genes로, 개별세포분석(scRNA-seq)에 있어 샘플 내 세포 간의 차이(embronic stem cells vs cancers)를 이해하는데 활용될 수 있다4)고 합니다.
저번 브릭 웨비나 '개별 세포 분석' 관련 강연 정리에서 강연자께서 말씀하신 "세포와 세포 간의 차이를 가장 잘 설명해줄 수 있는 기준이 되는 유전자"가 HVG가 아닐까 싶습니다.

참고로, sc-RNA seq의 과정 중 주성분 분석(PCA), UMAP을 활용한 시각화, cell clustering과 pseudotemporal trajectory inference와 같은 downstream anlyses 모두 선택된 HVGs에 의존하며, HVG 선택 통해 less formative features를 필터링하여 차원을 축소할 수 있다5)고 합니다.
HVG는 특정 세포에서 특이적으로 나타나는 유전자라면 특정 그룹에서 다른 그룹을 비교했을 때, 혹은 특정 조건과 다른 조건을 비교했을 때 '유전자 발현량'에 차이를 보이는 genes는 'Differentially Expressed Genes(DEGs)' 6)라고 합니다.
참고로 이러한 DEGs라는 유전자는 genotype(유전자형)과 phenotype(표현형) 수준*으로 구별할 수 있는 만큼, 샘플들 사이에서 해당 기준을 유전자형의 차이와 표현형의 차이 두가지 관점에서 양적 측정(quantitive measure)을 수행할 수 있다7)고도 하네요.
* 유전자형(genotype) vs (phenotype) : genotype은 특정 gene을 보유한 allels의 조합을 의미하고, phenotype은 유전자 발현으로 관찰될 수있는 charectisitcs 혹은 tratits의 조합을 의미8)합니다. 예로, 불면증과 관련된 정상 환자와 구별된 유전자의 조합은 불면증 genotype이라고 볼 수 있을 것이고, 불면증과 관련된 유전자 발현으로 불면증을 앓고 있는 환자의 traits의 조합은 불면증 pheonotype으로 볼 수 있지 않을까 싶습니다.
결국 HVGs와 DEGs 모두 세포들의 서로 다른 유형들을 분리하는 기준이 된다는 점에서 유사한 performance를 보입니다. 무엇이든지 간에 두 변수 간의 차이를 살펴보려면, 차이가 되는 명확한 '기준'이 있어야 할 것입니다. 이러한 차원에서 HVGs는 특정 세포에서 특이적으로 발현되는 유전자로서 샘플 내 어떤 세포가 분포하고 기능을 하는지 알려줄 수 있고, DEGs는 세포 간의 유전자 발현량의 차이를 알려주는 유전자로서 어떠한 세포가 분포하고 기능을 하는지 알려줄 수 있을 것입니다. 그럼으로써 설명력이 약한 유전자들은 제외하고 분석을 수행함으로써 즉, 차원을 축소함으로써 분석의 효율도 높여줄 수 있다고 하네요.
7. Single Cell RNA-seq data normalization
분석 대상 간의 차이를 파악하기 위한 분석을 수행하기 위해서는 어떤 것을 '차이'로 볼 것인지 기준을 잡는 것도 중요하지만 차이를 보고자 하는 대상에서 차이를 보고자 하는 부분이 아닌 부분은 '표준화'를 하는 것도 중요합니다.
예를 들자면, 익은 사과와 익지 않은 사과 중에 어떤 걸 초파리가 선호하는지 확인하는 연구를 수행한다고 하면 국적 별 사과를 비교하는 실험도 아닌데 하나는 한국 사과 하나는 미국 사과, 이렇게 하면 안되겠죠(한국 사과와 미국 사과에 차이가 있다는 전제 하에). 즉, 한 가지 나라에서 생성된 사과로 통일하고, 익었는지 안익었느지만 차이를 두고, 초파리가 무엇을 더 선호하는지 비교해야할 것입니다.

개별 세포 분석에 있어서도 'Quality Control' 과정에서 이러한 표준화 과정이 핵심으로 작용하지 않을까 싶습니다. 이러한 일환으로 진행되는 것이 'Data Normalization'입니다. 본 분석방법에 적용되는 첫번째 표준화 방법은 'size-factor normalization'인데요. 본 과정은 실험에 관찰하고자 하는 건 biological variation이지 technical variaiton이 아니기에, sequencing depth를 통일하는 표준화 과정8)이라고 합니다. 여기서 sequencing depth는 sequence의 copy number로 볼 수 있습니다.
즉, 샘플의 library size를 표준화함으로써 각 샘플의 reads의 total number 차이를 제거하기 위한 과정으로 볼 수 있다9)고 합니다. 이를 위해 cell-specific factor로 각각의 UMI count를 곱하여 모든 세포 샘플들이 각각 같은 UMI counts를 갖도록 한다 10)고 합니다.
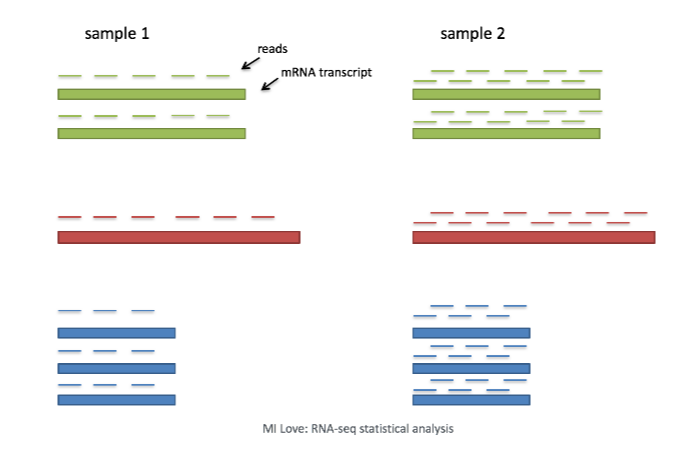
또 다른 표준화 방법으로 'log transformation'이 있는데, 이는 expression outilers에 의한 영향을 최소화하고 높은 발현량의 genes가 분석값을 독점하지 못하도록 하는 방법 8)이라고 합니다. 즉, log tansformation을 활용하여 low/medium abundance genes만 관찰하게 하는 것)입니다(보통 UMI의 수가 적은 세포(건강하지 못한 세포)들이 불균형하게 high abundance genes를 갖는다고 합니다 10)).
종합적으로 scRNA-seq 수행을 위한 preprocessing 즉, QC 과정에서 techincal artefacts나 low-quality cells를 제거하는 것은 물론, library의 sequencing depth와 gene expression의 abundance를 normalization하는 과정을 거치며 techincal noise와 biases를 제거하는 것이죠. 아래 영상에서 scRNA-data normalization 방법에 대해 소개해주는 것 같은데, 나중에 시간 될 때 봐야겠습니다. 아직 모르는게 너무 많네요.
어제 불꽃놀이 유튜브 생중계 영상 보면서 저 UMAP 시각화 한 모습이 떠올랐는데 정말 비슷해보입니다. 요즘 하루 일상이 거의 논문 공부가 전부다 보니 그렇게 보이는 것 같습니다.

다음에 또 논문을 공부하거나, 졸업 논문을 작성하면서 정리하고자 하는 개념들이 있으면 찾아오도록 하겠습니다. 감사합니다!
- 그 외 플러스 개념
1. single cell preparation에 필요한 재료들
1) EDTA(ethlene-diamin-tetraacetic acid) : 칼슘, 마그네슘과 같은 금속 이온과 결합하는 금송이온 봉쇄제(chelating reagent)로 금속이온이 필요한 nucleas를 불활성화시켜 DNA, RNA의 분해를 막는 역할 11)을 합니다. RNA-seq를 제대로 진행하려면, 그 과정에서 RNA degradation이 이루어지지 않도록 하는 보호 과정이 중요하기 때문으로 추측됩니다.
2) TryLE : lysine과 arginge의 펩티드 결합을 전달하는 역할을 하는 재조합 효소로, 포유류의 다양한 부착형 세포의 해리에 사용 12)할 수 있습니다 (동물 유래 성분이 없어 면역 거부반응으로부터 안전). 단일 세포분석에서는 세포들을 하나하나 구분해서 분석해야 하기에 사용했을 것입니다.
3) DMEM/F12 : 앞의 내용에서 설명
2. 상식 퀴즈
Q1. 왜 RNA-seq preprocessing 절차에서 mitochondial genes와 연관된 UMIs(Unique Molecular Identifiers)가 많은 세포들을 배제했을까?
: 세포가 자멸사하는 apoptosis 과정에서 보통 다른 cytoplasmic RNA는 잃지만 mitochondrial RNA는 잃지 않기 때문에 mitochondrial genes의 발현이 높게 나타나는 세포의 genes는 apoptic cells의 genes를 의미13)할 수 있기에 품질이 낮아 배제하는 것으로 추측됩니다.
3. 기타
1) False Discovery Rate (FDR) : 중요하다고 여겨지는 특징(signficant features)들 중 truly null인 비율로, FDR이 5%이면 significant한 모든 특징들 중 5%가 truly null임을 의미합니다 (false prediction / total prediction) 14).
# 읽고 있는 논문0)에선 0.05 이하의 FDR를 갖는 Genes를 HVGs로 정의했는데, 특정 세포에서 significant한 특정 유전자가 없는 비율 정도로 이해하면 되지 않을까 싶은데, 그냥 한 말이라 아닐 수도 있습니다.
참고자료
0) Jumee Kim et al. ,Partial in vivo reprogramming enables injury-free intestinal regeneration via autonomous Ptgs1 induction.Sci. Adv.9,eadi8454 (2023).
1) SeouLin Bioscience, DMEM(동물 세포 배양용 배지), URL : https://www.seoulin.co.kr/product/dulbeccos-modified-eagles-medium/
2) CacheBy, 솔바이오팜 DMEM/F12, URL : https://cacheby.com/@cacheby/products/%EC%86%94%EB%B0%94%EC%9D%B4 %EC%98%A4%ED%8C%9C-DMEM-F12-fekyy5lykv?srsltid=AfmBOoqcF26kdO1z-m8f8QLKFvTVKJZrTvgay5hN8l2P850H2Z lZJh4u
3) Thermo Fisher SCIENTIFIC, Factors Influencing Transfection Efficiency, Serum, URL : https://www.thermofisher.com/k r/ko/home/references/gibco-cell-culture-basics/transfection-basics/factors-influencing-transfection-efficiency.html
4) Yip SH, Sham PC, Wang J. Evaluation of tools for highly variable gene discovery from single-cell RNA-seq data. Brief Bioinform.;20(4):1583-1589. (2019).
5) Ruzhang Zhao, Jiuyao Lu, Weiqiang Zhou, Ni Zhao, Hongkai Ji. A systematic evaluation of highly variable gene selection methods for single-cell RNA-sequencing. bioRxiv. 2024.
6) Novogene, differentially expressed genes (DEG), URL : https://www.novogene.com/amea-en/resources/blog/how-to-employ-statistical-approaches-to-identify-differentially-expressed-genes-deg/
7) Bi Zhao, Aqeela Erwin, Bin Xue, How many differentially expressed genes: A perspective from the comparison of genotypic and phenotypic distances, Genomics, Volume 110, Issue 1, Pages 67-73, (2018).
8) 10X GENOMICS, Single-cell RNA-seq Data Normalization, 2023, URL : https://www.10xgenomics.com/analysis-guides/single-cell-rna-seq-data-normalization
9) Evans C, Hardin J, Stoebel DM. Selecting between-sample RNA-Seq normalization methods from the perspective of their assumptions. Brief Bioinform. 19(5):776-792. (2018).
10) Github, Single-cell RNA-seq: Normalization, identification of most variable genes, URL : https://github.com/hbctraining/ scRNA-seq_online
11) TAKARa, EDTA Buffer Powder, 제품설명, URL : https://www.takara.co.kr/web01/product/productList.asp?lcode=T9191
12) ThermoFisher SCIENTIFIC, TrypLE™ Express Enzyme (1X), no phenol red, URL : https://www.thermofisher.com/order/ catalog/product/kr/ko/12604013
13) 10X genomics, Why do I see a high level of mitochondrial gene expression?, URL : https://kb.10xgenomics.com/hc/en-us/articles/360001086611-Why-do-I-see-a-high-level-of-mitochondrial-gene-expression
14) COLUMBIA, False Discovery Rate, URL : https://www.publichealth.columbia.edu /research/population-health-methods/ false-discovery-rate




